A reference architecture for generating listing ads that won’t trip Fair Housing or a state disclosure rule. This architecture is coming from a real world use-case which anonymized and by the company and industry.
Most write-ups about generative marketing spend their wordcount on the model. Which checkpoint, which sampler, how many steps. That’s the easy part now — you can rent a state-of-the-art image model by the second and never touch a GPU. The hard part is everything wrapped around it: making sure the home in the picture is the actual property being advertised, making sure the copy doesn’t accidentally signal who’s welcome and who isn’t, and proving — to a brokerage, to a regulator, to your own legal team — that the ten thousand listing ads you generated last night are all defensible.
I’ve spent a while sketching out how I’d build a system that does this end to end, and the interesting design decisions almost all live in that wrapper. This post is the whole thing, top to bottom: the problem, the two ideas that shape the architecture, the generation pipeline, the compliance layer, evaluation, and how you’d scale it without rewriting it. I’ll define the jargon as it comes up and link out so you can go deeper, and I’ll be honest about which parts are genuinely hard versus which parts are a solved API call in 2026.
If you build platforms for a living, the shape will feel familiar. The real-estate specifics are what make it interesting — and what make it legally spiky.
Why real-estate advertising is a nasty compliance problem
A listing ad has to satisfy two completely independent rule systems at once, and people new to the space usually only notice one of them.
The first is brand and brokerage compliance. Most agents operate under a franchise brand with strict standards — logo usage, approved colors, how an agent’s name and designations can appear. The REALTOR® trademark itself has tight usage rules set by the National Association of REALTORS: who can use it, how it’s capitalized and punctuated. On top of that, local MLS and board rules govern how a listing may be advertised at all — chiefly that you must attribute the listing brokerage and can’t represent someone else’s listing as your own. Get this wrong and you’re looking at brand sanctions, board fines, or removal from the MLS feed your whole business depends on.
The second is legal compliance, and this is the one that bites. The Fair Housing Act prohibits advertising that indicates a preference or limitation based on race, color, religion, sex, disability, familial status, or national origin — and it applies to both words and pictures. The words part is subtler than people expect: “perfect for a young family,” “safe, quiet neighborhood,” “walking distance to St. Mary’s,” “exclusive enclave,” “ideal for bachelors” can each be read as steering or as signaling who belongs. The federal rules on discriminatory advertising are spelled out in 24 CFR §100.75. Then states layer on their own disclosure requirements — the licensee’s name, the brokerage, a license number, often the Equal Housing Opportunity logo or slogan. If the ad mentions financing terms, Regulation Z (Truth in Lending) applies on top.
Here’s the trap: the brand review checks the brand rules. It does not check whether your ad is legal under Fair Housing law — that obligation lands on the broker and agent, separately. So an ad can be flawlessly on-brand and still a Fair Housing violation. (And this isn’t theoretical in 2026: automated housing advertising is under specific regulatory scrutiny after the Department of Justice’s settlement with Meta over discriminatory ad delivery, which is why housing is now a restricted ad category on the major platforms. If you’re building an algorithm that touches housing ads, assume someone will eventually audit it.)
The architectural consequence is the first big idea, and everything downstream depends on it:
Brand compliance and Fair Housing compliance are two separate axes. You need two parallel rule sets and two parallel validators, not one merged “compliance check.”
The second idea: never generate the home
The obvious way to build a generative listing-ad engine is to prompt an image model — “a beautiful staged living room in a four-bedroom colonial” — and ship what comes out. This is also the obvious way to get a misrepresentation complaint.
A diffusion model (the family of models behind essentially all modern image generators — they work by starting from noise and iteratively denoising toward an image that matches your prompt) will happily invent a home that doesn’t exist. Advertising a property that isn’t the actual listing — wrong room, wrong layout, a fireplace that isn’t there — is deceptive advertising, an ethics violation, and a fast way to lose a license. So you don’t generate the home. You source the real listing photos, and you only stage them.
That’s the second idea:
Don’t generate the property. Source it, stage it, and disclose the staging.
Virtual staging — adding furniture and decor to a real photo of an empty room — is legitimate and widespread, but it’s governed: many MLS and state rules require you to disclose that an image was virtually staged or materially altered, precisely so a buyer isn’t misled. So the generative model gets to add furniture into empty space; it never gets to invent or alter the room’s actual structure, and the output carries a “virtually staged” label. The principle generalizes: let generative models handle the parts where a small imperfection is cosmetic, and keep deterministic control over the parts that have to be true.
Hold onto those two ideas. They explain almost every decision below.
The system at altitude
Here’s the whole thing as one picture before we drill in.
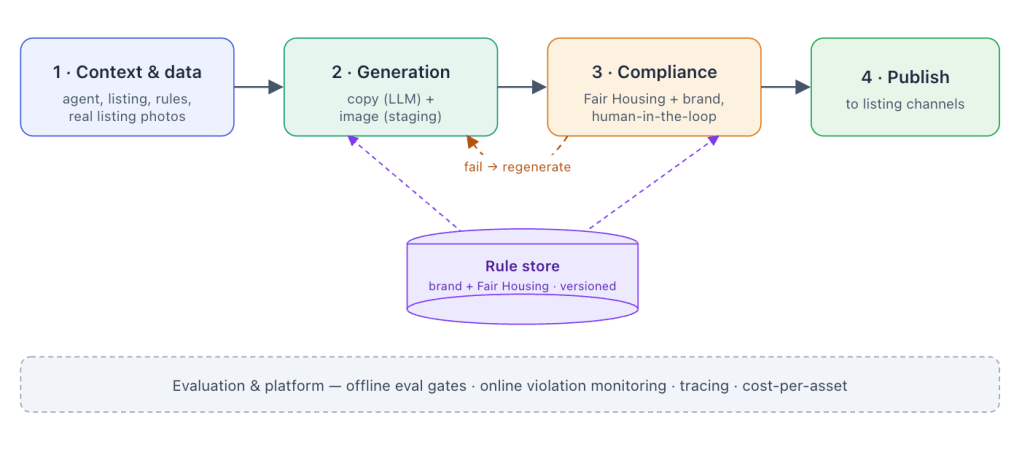
Figure 1 — The runtime spine flows left to right; the rule store feeds both generation and compliance; evaluation and platform run underneath everything.
A single ad job walks across that spine: gather the context for this agent and listing, generate the copy and the image, run it through the compliance gates, and — only if it passes — publish. The rule store sits in the middle because the same rules shape generation (we tell the model the constraints up front) and enforcement (we check the output against them). Underneath, evaluation and platform concerns hold the whole thing accountable.
Let me take the three interesting subsystems one at a time: generation, compliance, and evaluation.
Generation, part one: the copy
Listing copy is text, so the instinct is to let a large language model write it freely. Don’t — at least not the parts that carry legal weight.
The move that makes this safe is structured output: instead of asking the model for a paragraph, you ask it to fill a typed schema. Pydantic AI is a clean way to do this in 2026 — you define a schema (headline, description, call-to-action, the required disclosures) and the framework constrains and validates the model’s response against it. The descriptive prose is generated. The things that must be true — the bed and bath count, the square footage, the address, the brokerage and license disclosures — are not generated at all. They’re pulled from the MLS listing data and the rule store and dropped into named slots verbatim.
That distinction kills two failure modes at once. The model can’t misstate the square footage, because it never gets to type a number — misrepresenting size is a classic source of liability. And the required disclosures can’t be silently dropped, because they’re structural fields, not something the model chose to include.
The more insidious risk in this domain isn’t a wrong number, it’s wrong language — the model’s natural inclination to write “perfect for a growing family” or “quiet, safe street,” which are textbook Fair Housing problems. So prohibited-language constraints go into the prompt, and — because prompts leak — the output is checked again afterward (more on that under compliance).
Which rules and disclosures apply is decided by retrieval — specifically RAG, retrieval-augmented generation, where you fetch relevant context and feed it to the model rather than relying on what it memorized. One nuance worth saying out loud, because the reflexive answer is wrong: most of this retrieval isn’t fuzzy semantic search. When a job comes in you already know the state, the brokerage, the listing type, and the channel, so the applicable rules are a precise database query — a WHERE clause, not a vibe. You want all the applicable rules, deterministically and auditably, not a top-k guess. Vector search earns its place only as a complement, for catching paraphrased problems — the steering language a fixed word-list would miss.
Generation, part two: the image
This is where the “don’t generate the home” idea becomes a concrete pipeline. The key realization is that it’s a mix of models and plain code, split on purpose: models make it look real; code makes it true.
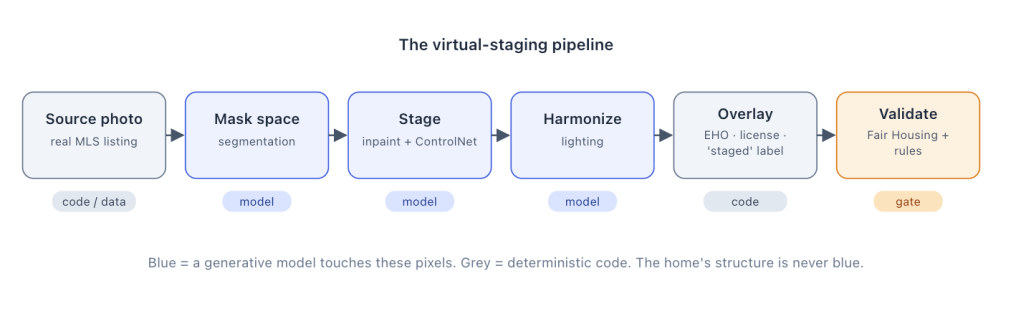
Figure 2 — A model adds the furniture and fixes the lighting; code handles sourcing, the disclosure overlay, and validation; the home’s structural pixels are never model-generated.
Walking it left to right:
Source the photo. Pull the real listing photo from the MLS, keyed by listing ID. These are the ground truth — the actual room being sold. If you need to isolate a region cleanly, that’s a job for a matting / segmentation model (BiRefNet and Meta’s SAM 2 are the current go-tos), used to find the empty floor space rather than to invent anything.
Stage it. Now the model gets to work, but only inside the empty space. The technique is inpainting — generating new content into a masked region while everything outside the mask stays pixel-for-pixel identical. You mask the bare floor and generate furniture into it; the walls, windows, and the actual architecture are untouched. To keep the staged furniture sitting correctly in the room’s perspective, you condition the model with ControlNet on a depth map of the room — ControlNet constrains a diffusion model to follow a structural map (edges, depth) so the output respects a geometry you specify. Two more tools earn their keep: LoRA (low-rank adaptation) is a tiny, swappable fine-tune you can train per design aesthetic — mid-century, farmhouse, Scandinavian — without retraining the whole model; and IP-Adapter lets a reference image drive the style with no training at all, handy for matching a brokerage’s signature look. The model choice itself is a routing decision: SDXL is cheap, fast, and has the deepest control-tooling ecosystem, while FLUX from Black Forest Labs is more photorealistic — you pick per job.
Harmonize. Freshly inpainted furniture can carry lighting that doesn’t match the room. IC-Light, a diffusion-based relighting model (from the author of ControlNet) available as a hosted endpoint in 2026, harmonizes the added elements to the room’s actual light. This is polish; if it fights you, a clean inpaint is perfectly shippable.
Overlay. The most important step for compliance, and there’s no model anywhere near it. The Equal Housing Opportunity logo, the brokerage name and license number, and — critically — the “Virtually Staged” label are rendered by a deterministic templating engine (a graphics library, or HTML/CSS rendered to an image) from structured data. Because you drew these pixels yourself from known strings, they’re exact, and — crucially — they’re checkable.
Validate. Off to the compliance layer.
On infrastructure: in 2026 you don’t need to host any of these models to build this. Platforms like fal.ai expose SDXL and FLUX inpainting with ControlNet and LoRA, BiRefNet matting, and IC-Light relighting as plain API calls billed per image or per second. The entire image stack can run without a single GPU under your control — which means the engineering effort goes where it should, into the orchestration and compliance, not into ops.
Compliance: layered guardrails
This is the part you’re actually hired to build. The principle is simple and it’s about money: run the cheap checks first, the expensive checks second, and send only the ambiguous cases to a human.
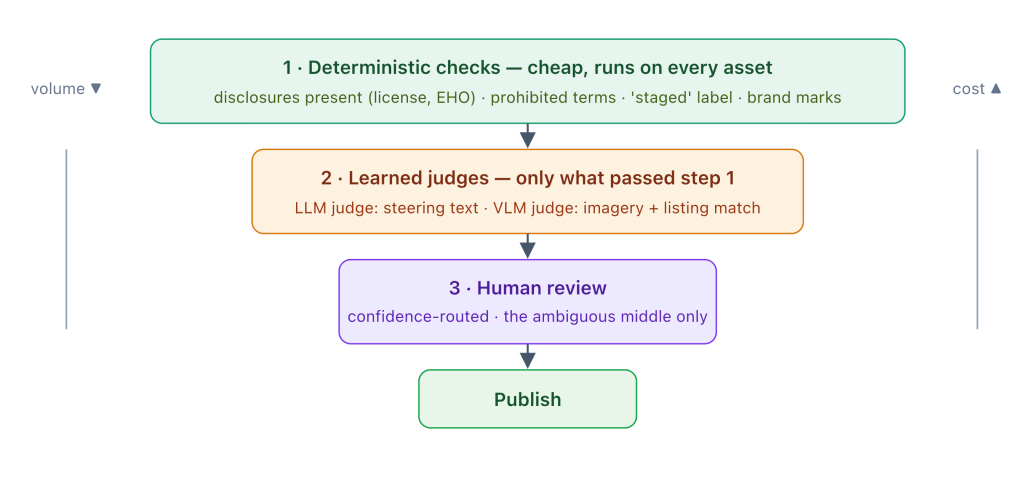
Figure 3 — Each layer is more expensive than the last and sees fewer assets. Most violations are caught for free at the top; humans only see the residue.
Deterministic checks are symbolic and they run on every single asset. Are all the required disclosures present — brokerage, license number, Equal Housing Opportunity mark? Is the “Virtually Staged” label on any altered image? Does the copy contain any term from the Fair Housing red-flag list (“exclusive,” “restricted,” “perfect for,” “no children,” religious or ethnic references)? Are the brand marks used correctly on the overlay? You can answer all of these with regular expressions and pixel inspection precisely because you rendered the overlay deterministically. These checks are nearly free, so they go first, and an asset that fails one is rejected and regenerated before you’ve spent a cent on anything smarter. Both the brand validators and the legal validators live here, kept separate per the two-axis idea.
Learned judges handle what symbols can’t. This is LLM-as-judge — using one model to grade another’s output against a rubric. A word-list will never catch every steering phrase; “great bachelor pad,” “walk to the synagogue,” “a real family street” are all problems no regex anticipates, and that’s exactly where a judge with a Fair Housing rubric earns its place. The image gets a VLM-as-judge (vision-language model) pass for the parts of Fair Housing that live in pictures: does the imagery signal exclusion or preference, does the staged room misrepresent the actual space, does the photo even match the listing? Tooling like DeepEval gives you the metric scaffolding — G-Eval for scoring against natural-language criteria, and a decision-graph metric for staged checks where you want deterministic branching (“if a disclosure is missing, stop; else check for steering language; else score tone”). These judges are not infallible — they have known biases toward longer or first-listed answers — so you calibrate them against a labeled set, ensemble them for high-stakes verdicts, and never let them be the only line of defense. The cheap deterministic layer is always the floor.
The output of the judges isn’t a hard yes/no; it’s a confidence. That feeds the third layer.
Human review, confidence-routed. High confidence publishes automatically. Low confidence is auto-rejected and regenerated. The genuinely uncertain middle goes to a person. This routing is the whole economic argument for the system: a brokerage or marketing operation spends real money on manual creative and compliance review, and you don’t eliminate the humans — you point them at the few percent of cases that are actually ambiguous instead of every single ad.
One security note people forget. Some inputs here are agent-supplied — a custom tagline, an open-house blurb — and untrusted input flowing into an LLM is a prompt-injection surface (see the OWASP Top 10 for LLM Applications). Treat agent text as data, never as instructions; keep the legal strings templated so they can’t be overridden by anything the model emits; and validate outputs independently of the model that produced them.
The rule store is the actual product
Everything above leans on a thing I’ve been calling the rule store, and it’s worth saying plainly: this is the hard part and the defensible part. The models are commodities. The MLS feeds and image tools are vendors. What’s hard is turning fuzzy Fair Housing guidance and dense state disclosure law into checks a legal team will actually trust, and keeping them current as rules and brand standards change.
The design that makes this tractable: store each rule as a triple. A plain-language statement (which gets injected into the generation prompt and used as the judge’s rubric), a validator (code or regex, for the rules that are objective), and a set of test cases (positive and negative examples). Key every rule by scope (brand or legal), franchise, jurisdiction, listing type, and an effective date, and version the whole thing. Legal authors the rules in plain language; you compile them into validators and retrieval chunks; nothing reaches production without passing a regression suite. When a state changes a disclosure requirement, you bump the version and re-validate the ads already in flight. That last property — a rule change automatically flags non-compliant live ads — is the kind of thing that turns a demo into a system people depend on.
Evaluation: how you sleep at night
A compliance system you can’t measure is a liability with extra steps. Two loops.
Offline, you build a golden set — historical listing ads labeled approved or rejected — and track pass rates per rule, per state, per brokerage. This suite runs as a gate in CI: no model, prompt, or rule change ships unless it passes. A bad batch should be caught here, by your own tests, not in production by a platform rejecting your housing ads or, worse, a complaint.
Online, the truth signals are ad-platform rejections (the major channels actively police housing creative), agent and consumer complaints, and drift monitors on rules, models, and feeds — plus the boring-but-essential business metrics (does compliant creative still perform? watch click-through and cost-per-lead per variant). Every production miss becomes a new test case in the offline set. That feedback loop, more than any single model choice, is what makes the thing improve over time.
Making it scale without rewriting it
A quick reality check on volume. Picture a few thousand agents, each with a handful of live listings, several ad formats and channels, refreshed as listings change. That’s easily hundreds of thousands of assets a week — a steady stream with sharp peaks when a big brokerage refreshes its inventory. At a few seconds per image, that’s a fleet-sizing and caching problem, not a model problem.
The biggest lever isn’t a faster model; it’s not generating the same thing twice. The same room staged in the same style produces the same image — so you generate it once and reuse it across the channels and formats that only differ in the templated overlay. Non-urgent jobs run on cheaper preemptible compute; a just-listed property jumps the queue. And you track cost-per-asset as a first-class metric, because diffusion isn’t free and the whole pitch is that you’re cheaper and faster than the manual process you replaced.
For orchestration, I’d reach for a durable workflow engine — Temporal is the obvious fit — because the dominant requirement is reliably running many retryable, idempotent jobs where the publish step has to happen exactly once. You can nest LangGraph inside a workflow step for the multi-step LLM reasoning. What I would not do is build this as a swarm of autonomous agents. This is a high-throughput pipeline with well-defined stages, not an open-ended reasoning task, and deterministic workflows beat agents here on cost, latency, and debuggability. Saying that out loud tends to surprise people in 2026, which says more about the current hype than about the problem.
The design principle that keeps “scale later” from meaning “rewrite later”: write each generation step as a pure, idempotent function behind a typed interface, and hide every external dependency (the database, the image API, the judge) behind a thin provider interface. Then scaling up is swapping implementations — a bigger queue, a managed Temporal, a self-hosted GPU pool — without touching the core logic. Start on managed Postgres with pgvector for retrieval rather than a separate vector database; the rule corpus is small and dominated by metadata filtering, and you can graduate to something specialized if and when measurement says you must.
What’s actually hard, and what I’d skip
Three things are genuinely hard, and none of them are the AI.
Getting the rights and clean access to listing photos is a data and licensing problem (MLS and IDX rules), not an engineering one. Authoring Fair Housing rules a legal team trusts is slow, human, and never finished — the language cases are endless and the stakes are high. And tuning the confidence thresholds so automation expands safely — loosening only as your measured violation rate stays flat — is a judgment call you’ll work on for months.
A few things I’d deliberately skip, especially early. Don’t train a foundation model; rent one. Don’t build a general home-generating image model; source and stage. Don’t reach for multi-agent orchestration; use workflows. And don’t let anything auto-publish without the gate. The boldness in this system should all be spent on the compliance engine. Everything else should be boring on purpose.
Takeaways
If you remember four things from this: brand compliance and Fair Housing compliance are separate problems and need separate enforcement. You never let a generative model draw the regulated object — you source the real listing and only stage it, disclosed. Guardrails are layered cheapest-first with humans on only the ambiguous middle. And the rule store, not the model, is the part that’s actually worth building. The models are a commodity you rent by the second in 2026. The system that makes their output trustworthy at scale is the thing with the moat.
Glossary & further reading
- Diffusion / latent diffusion model — the model family behind modern image generators; denoises from random noise toward a prompt-matching image. Rombach et al., 2022
- SDXL — a widely-used open diffusion model with a deep control-tooling ecosystem. Podell et al., 2023
- FLUX — a 2024+ diffusion-transformer family with strong photorealism and in-image text. Black Forest Labs
- Inpainting — generating content into a masked region while keeping the rest of the image fixed. Diffusers docs
- ControlNet — conditions a diffusion model on a structural map (edges, depth) to control layout. Zhang et al., 2023
- LoRA (low-rank adaptation) — a small, swappable fine-tune; here, one per design aesthetic. Hu et al., 2021
- IP-Adapter — drives style from a reference image with no training. Ye et al., 2023
- BiRefNet / SAM 2 — high-resolution matting and segmentation. BiRefNet · SAM 2
- IC-Light — diffusion-based relighting / illumination harmonization. Project repo
- RAG (retrieval-augmented generation) — fetch relevant context and feed it to the model at inference. Lewis et al., 2020
- Structured output / Pydantic AI — constrain model output to a typed schema. Pydantic AI docs
- LLM-as-judge — use a model to grade another model’s output against a rubric. Zheng et al., 2023
- G-Eval / DeepEval — evaluation metrics and harness for LLM systems. DeepEval · G-Eval
- OWASP Top 10 for LLM Applications — security risks including prompt injection. OWASP GenAI
- Temporal / LangGraph — durable workflow orchestration, and graph orchestration for LLM steps. temporal.io · LangGraph
- pgvector — vector search inside Postgres. Project repo
- Real-estate ad law — Fair Housing Act; discriminatory-advertising rules at 24 CFR §100.75; NAR Code of Ethics; Regulation Z where financing is advertised.
