Two of them run your model. One of them runs a fleet of the other two. Here’s how the layering actually works — and how to choose.
I keep seeing this comparison framed as a three-way cage match — pick vLLM or TensorRT-LLM or Ray Serve, may the best framework win. And every time, I want to gently stop the conversation, because the framing is broken before it starts.
Two of these things run your model on the GPU. The third one doesn’t run a model at all — it wraps one of the other two and manages a fleet of them. Comparing all three head-to-head is like asking whether you should use a car engine, a different car engine, or a fleet dispatcher. The dispatcher question is real, but it’s a different question.
So this post does two things. First, it untangles the layering so the “versus” actually means something. Then it goes deep — high level down to the scheduler internals — on what each piece really does, what the jargon means (I’ll define the concepts as they come up, because I wasn’t fully comfortable with all of them either when I started), and how you’d actually choose. I’ve pulled in the other engines and orchestrators that matter too, because in 2026 the picture is wider than three names.
Let me start with the one mental model that fixes everything.
The stack, not the showdown
Here’s the layering that makes the rest of this post click:
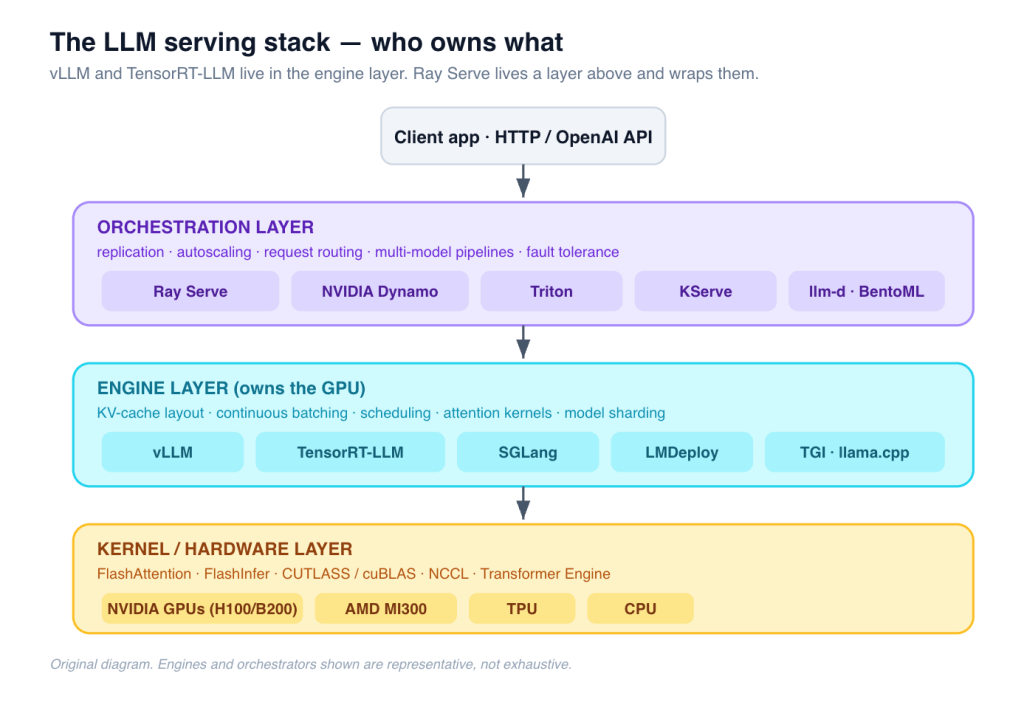
Figure 1 — The serving stack. vLLM and TensorRT-LLM live in the engine layer and own the GPU. Ray Serve lives a layer up and wraps them. (Original diagram.)
- vLLM and TensorRT-LLM are inference engines. They own the GPU. They decide how the KV cache is laid out, how requests get batched on each forward pass, which CUDA kernels fire, how the model is split across devices. This is the layer where tokens-per-second is won or lost.
- Ray Serve is a serving / orchestration framework. It never runs a forward pass. It takes an engine — almost always vLLM — and adds replication, autoscaling, request routing, multi-model pipelines, and fault tolerance across a cluster.
Once you see it this way, the real questions fall out naturally:
- Which engine? vLLM vs TensorRT-LLM vs SGLang vs the rest. This is a genuine fight.
- Do I even need an orchestrator? And if so, is Ray Serve the right one, or is it NVIDIA Dynamo, Triton, llm-d, or nothing at all?
The rest of the piece works through both.
Quick definitions before we go deeper (skip if these are old hat):
- KV cache — when a transformer generates text, every new token attends back to every previous token. Rather than recompute the keys and values for the whole history on every step, the model caches them. That cache grows with sequence length and eats most of your GPU memory at serving time. Managing it well is the game. (Good primer.)
- Prefill vs decode — two phases of a request. Prefill processes your entire prompt in one big parallel pass (compute-bound). Decode then generates output one token at a time (memory-bandwidth-bound). They behave so differently that a lot of modern tricks exist purely to stop them from interfering with each other.
- Throughput vs latency — throughput is total tokens/sec across everyone; latency is how fast one user gets served, usually measured as TTFT (time to first token) and TPOT/ITL (time per output token, a.k.a. inter-token latency). Optimizing one often hurts the other.
Part 1 — The high-level profiles
vLLM — the open-source default
Came out of UC Berkeley’s Sky Computing Lab and made PagedAttention famous (SOSP 2023). It’s Apache-2.0, vendor-neutral, runs on NVIDIA, AMD, TPU, and even CPU, and supports 200+ model architectures straight off HuggingFace. pip install vllm, point it at a repo, and you’ve got an OpenAI-compatible endpoint in about a minute. It’s now under LF AI & Data governance and has effectively become the reference engine — to the point where the other tools in this post are built to wrap it.
The bet: maximize throughput-per-dollar on whatever hardware you’ve got, with the shortest path from nothing to a running endpoint. Flexibility first; the last 10% of peak performance second.
TensorRT-LLM — NVIDIA’s performance ceiling
NVIDIA’s library for wringing every last drop out of NVIDIA GPUs. For most of its life this meant ahead-of-time compilation: you converted a checkpoint and ran a build step that produced a hardware-specific engine with fused, autotuned kernels. That path still exists — but the project went through a serious identity change. TensorRT-LLM 1.0, released September 24, 2025, made a PyTorch-native backend the default and stable experience, with a stable high-level LLM API and an OpenAI-compatible trtllm-serve that no longer forces an explicit build step.
This is the single most out-of-date thing in most comparisons you’ll read: the “TensorRT-LLM means a painful compile step” narrative now describes the legacy path, not the default. The usability gap with vLLM narrowed a lot in late 2025.
What you still get that nothing else matches: hand-tuned CUDA kernels per GPU architecture, the most mature FP8/FP4 support via the Transformer Engine on Hopper/Ada/Blackwell, the broadest speculative-decoding menu, and tight integration with Triton and NVIDIA Dynamo.
The bet: if it runs on an NVIDIA GPU and you’ll do a bit of work (less now than before), you get the best latency and peak throughput available.
Ray Serve — the orchestration layer
Part of the Ray ecosystem (Anyscale). Ray Serve is a framework-agnostic, Python-native serving library: you write @serve.deployment classes, each becomes an independently scalable pool of Ray actors, and you compose them into graphs. Ray Serve LLM is the specialization that wraps an engine (vLLM or SGLang) and adds horizontal scaling, queue-depth autoscaling, prefix/session-aware routing, and orchestration of the gnarly distributed topologies — disaggregated prefill/decode, wide expert parallelism — across many nodes.
The bet: the engine is a component, not the system. Own everything around the forward pass — placement, scaling, composition, fault tolerance — and stay engine-agnostic.
| vLLM | TensorRT-LLM | Ray Serve | |
|---|---|---|---|
| Layer | Inference engine | Inference engine | Orchestration framework |
| Maker | Berkeley → LF AI / community | NVIDIA | Anyscale / community |
| License | Apache 2.0 | Apache 2.0 | Apache 2.0 |
| Hardware | NVIDIA, AMD, TPU, CPU | NVIDIA only | Whatever the engine supports |
| Owns the GPU? | Yes | Yes | No — wraps an engine |
| Default API | OpenAI-compatible server | trtllm-serve (OpenAI-compatible) | FastAPI / OpenAI-compatible ingress |
| Core bet | Flexibility + throughput/$ | Peak perf on NVIDIA | Scaling & composition |
Part 2 — vLLM, all the way down
PagedAttention: virtual memory for the KV cache
This is the idea that started it all, and it’s genuinely elegant once it clicks.
The problem it solves: naive serving pre-allocates one contiguous block of memory per request, sized for the maximum sequence length it might reach. If your ceiling is 4,096 tokens but the average request only uses 512, you’ve reserved — and stranded — the other ~87%. That wasted VRAM directly caps how many requests fit at once, which caps batch size, which caps throughput. Memory you’re not using is throughput you’re not getting.
PagedAttention borrows the trick every operating system already uses for RAM. Split the KV cache into small fixed-size blocks (16 tokens each by default, set with --block-size). Each sequence addresses its cache through a block table that maps logical positions to non-contiguous physical blocks — exactly how a page table maps virtual pages to scattered physical frames.
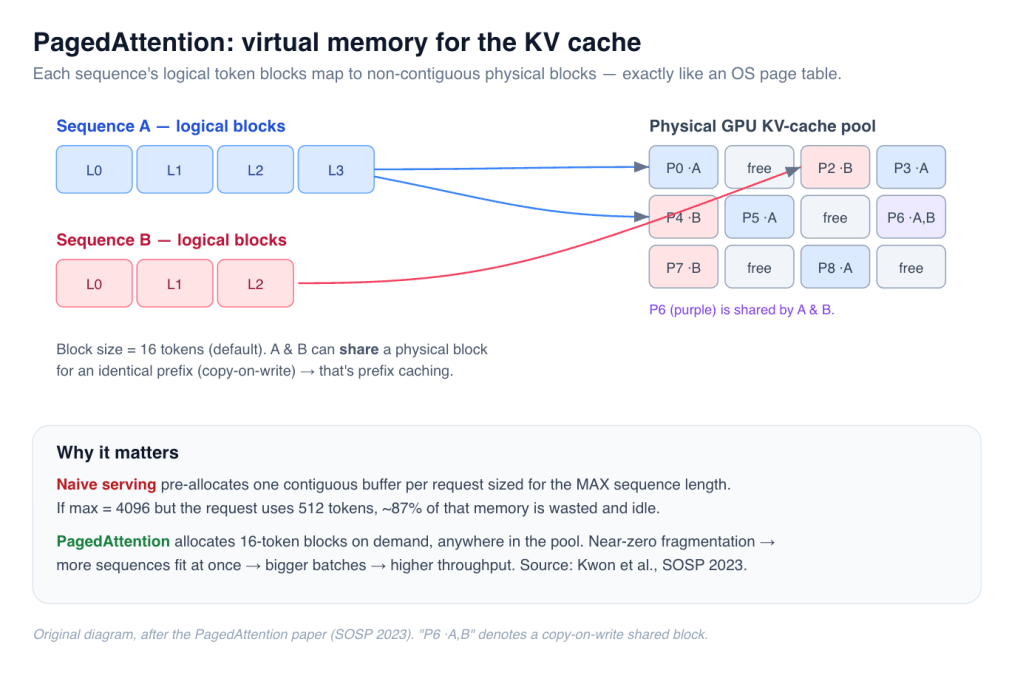
Figure 2 — Each sequence’s logical blocks map to non-contiguous physical blocks. A shared prefix can point at the same physical block (copy-on-write). (Original diagram, after Kwon et al., SOSP 2023.)
Three things fall out of this for free:
- Near-zero fragmentation. Blocks are allocated on demand, so there’s no per-request over-provisioning.
- Copy-on-write sharing. Parallel samples, beam search, and identical system prompts can share physical blocks until they diverge, then copy only the block that changes.
- Prefix caching. Thousands of requests that start with the same 2,000-token system prompt map to the same physical blocks, so that prefill compute happens once.
Why this is the headline feature: it’s the difference between fitting 8 concurrent sequences on a GPU and fitting 40. Everything else vLLM does sits on top of having solved memory first.
Continuous batching: keep the GPU fed
Memory was half the battle. The other half is scheduling.
The old way — static batching — locks the GPU to a fixed batch until the slowest request in it finishes. Short requests sit around twiddling their thumbs while one long generation drags out, and the GPU idles on all those finished slots. It’s the checkout line where nobody can leave until the person with the overflowing cart is done.
vLLM does continuous batching (a.k.a. iteration-level scheduling, an idea from the Orca paper, OSDI 2022). The scheduler re-decides on every forward pass. The instant a sequence emits its end token, its slot frees and a queued request slides in on the very next step.
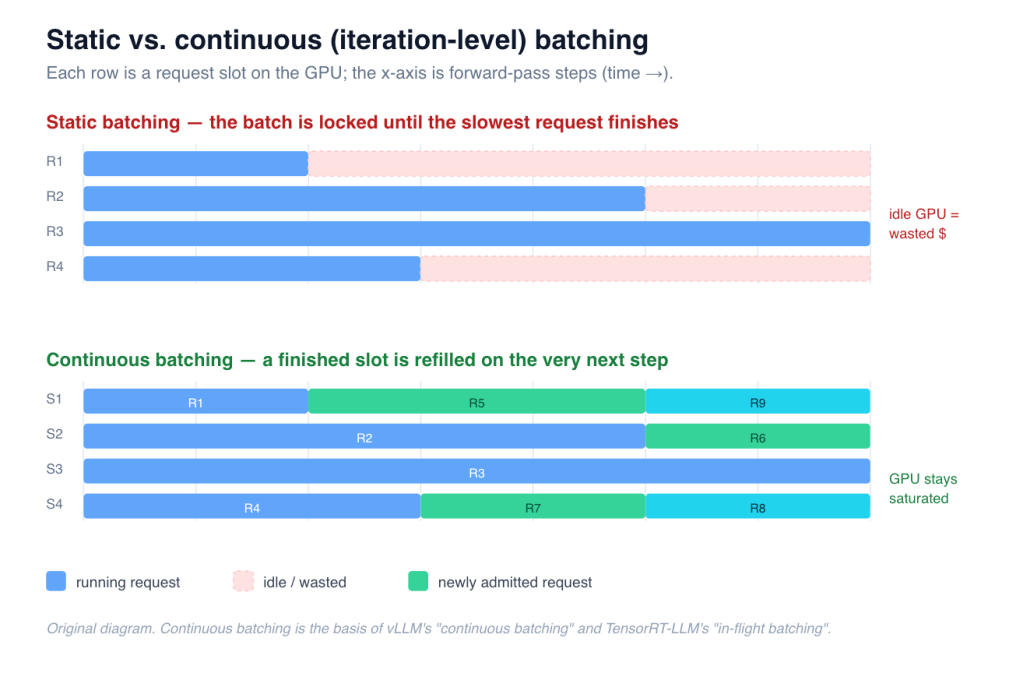
Figure 3 — Static batching strands the GPU on finished slots; continuous batching refills them immediately. (Original diagram.)
This is where the often-cited “up to 23× throughput over naive batching” comes from — the GPU stays saturated step after step instead of constantly draining and refilling. TensorRT-LLM does the same thing under the name in-flight batching; same idea, different code.
Chunked prefill: stop big prompts from starving everyone
Prefill can be long, and decode is sensitive to interruption. If a giant 8K-token prompt monopolizes a forward pass, every in-flight decode stalls, and users feel it as latency spikes. Chunked prefill (SARATHI, 2023) chops a long prompt into pieces and interleaves them with ongoing decodes. It nudges median TTFT up slightly (the cost of interleaving) but flattens the p95 tail dramatically — and the tail is what users actually complain about. In vLLM’s V1 engine it’s on by default.
The V1 rewrite: when Python becomes the bottleneck
By 2024, vLLM had a counterintuitive problem: the GPU kernels were fast, but the Python running between forward passes — scheduling, sampling, assembling outputs — was eating the gains at high concurrency. The V1 engine (rolled out through 2025, now the default) is a ground-up rework to fix exactly that. Worth knowing:
- An isolated
EngineCoreloop runs in its own process, talking to the API server over ZeroMQ so CPU work overlaps the GPU instead of blocking it. - A unified scheduler drops the hard prefill/decode split and treats prompt and output tokens the same way, via a simple per-request token budget. This is what lets chunked prefill, prefix caching, and speculative decoding compose cleanly instead of fighting.
- Simplifications: KV-cache swapping to CPU is gone (paging makes preemption cheap enough without it). An encoder cache keeps vision embeddings alive across chunked steps for multimodal models.
If you want the genuinely excellent deep read on the internals, Aleksa Gordić’s “Inside vLLM” walks the V1 code path better than I could here.
Disaggregated prefill/decode: the frontier pattern
Prefill is compute-bound; decode is memory-bandwidth-bound and latency-sensitive. Run them on the same GPU pool and they interfere. Disaggregation (Splitwise and DistServe, 2024) puts prefill on one pool and decode on another, shipping the KV cache between them over the network.
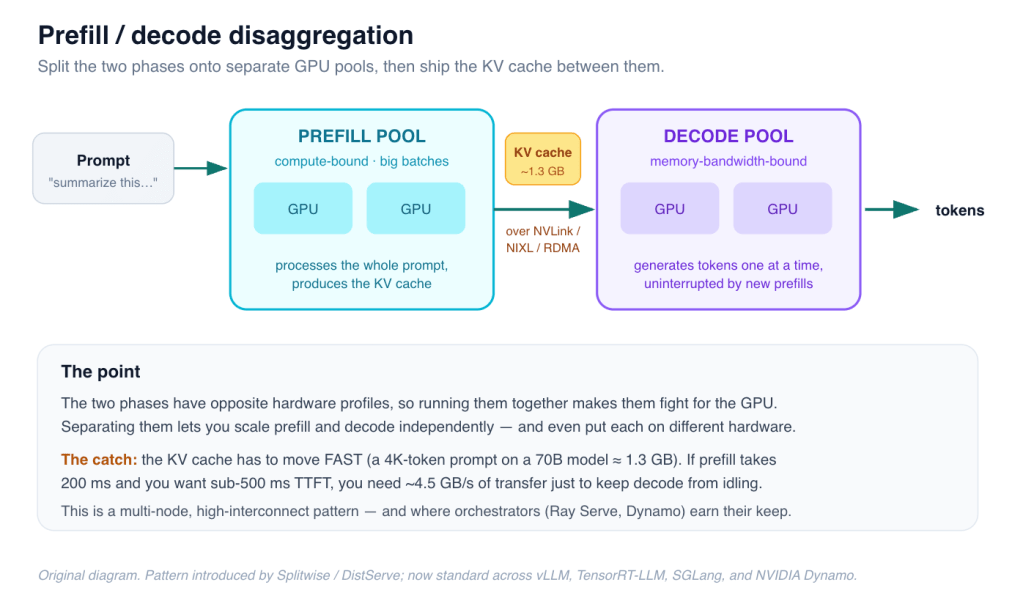
Figure 4 — Split the phases onto separate GPU pools and move the KV cache between them. The transfer bandwidth is the hard part. (Original diagram.)
The payoff is independent scaling of the two phases and even using different hardware for each. The catch is bandwidth: a single 4K-token prompt on a 70B model is roughly 1.3 GB of KV cache, and it has to move fast enough that the decode worker isn’t left idle. That’s why this is a multi-node, high-interconnect pattern — and, not coincidentally, exactly where an orchestrator starts to earn its place.
vLLM quantization & parallelism, briefly
Quantization = storing weights (and sometimes activations and the KV cache) in fewer bits — FP8, INT4, etc. — to cut memory and speed up math, at a small accuracy cost. AWQ/GPTQ are popular weight-only 4-bit schemes; FP8/FP4 use dedicated hardware on newer NVIDIA GPUs.
vLLM supports FP8, AWQ, GPTQ, INT8, and FP4/NVFP4 on Blackwell, plus an FP8 KV cache. For splitting big models it offers tensor parallel, pipeline parallel, and data-parallel attention + expert parallel for large MoE models like DeepSeek-V3. Multi-node coordination runs through a Ray executor backend by default.
The parallelisms, in one breath: tensor parallel splits each layer across GPUs; pipeline parallel puts different layers on different GPUs; expert parallel spreads a Mixture-of-Experts model’s experts across GPUs; data parallel runs full replicas side by side. Real deployments stack several of these.
Part 3 — TensorRT-LLM, all the way down
Two workflows, and why the second one changed the conversation
For years, TensorRT-LLM meant one workflow — the compiled-engine path:
- Convert HF weights to a TRT-LLM checkpoint, choosing dtype and quantization.
- Run
trtllm-buildto compile that checkpoint into a TensorRT engine — a serialized CUDA kernel graph autotuned for one GPU SKU, a fixed max batch size, and a fixed max sequence length. - Serve it, usually through Triton’s TensorRT-LLM backend.
The upside is hand-tuned-C++ performance. The downside is structural: change the model, the batch ceiling, the sequence length, or the GPU, and you rebuild — and that build runs on the order of tens of minutes. (That’s the “~28-minute cold start” you’ll see in benchmarks.) For a stable, high-traffic, single-model service, it’s a one-time cost you amortize forever. For a team swapping models every week, it’s friction on every change.
Then 1.0 (September 2025) flipped the default. NVIDIA re-architected onto a PyTorch-native backend, and now you can do this:
python
from tensorrt_llm import LLM, SamplingParamsllm = LLM(model="nvidia/Llama-3.1-8B-Instruct-FP8") # HF repo or quantized checkpointout = llm.generate(["The capital of France is"], SamplingParams(temperature=0.8))
…and trtllm-serve defaults to that PyTorch backend, handing you an OpenAI-compatible server with no explicit trtllm-build. The forward pass still runs TRT-LLM’s optimized kernels; model definition and runtime are just PyTorch-native now, so the day-to-day feels much closer to vLLM. The compiled path stays available for squeezing out the final few percent.
NVIDIA’s own engineers tell this story candidly in the 1.0 retrospective — the original compiler-centric, ONNX-flavored design fought badly against the stateful KV cache and dynamic batching, so they pivoted to using TensorRT for the forward pass and PyTorch for everything around it.
Why it’s fast: NVIDIA owns the whole column
- Hand-tuned fused CUDA kernels for attention, GEMMs, and MoE, maintained per architecture (Hopper SM90, Blackwell SM100, and so on).
- First-class FP8/FP4 through the Transformer Engine — dedicated low-precision tensor cores that roughly double throughput and halve memory versus BF16 at under ~1% quality loss. This is the clearest structural edge TRT-LLM has, because it’s co-designed with the silicon.
- CUDA graphs + torch.compile + piecewise graph capture in the PyTorch backend to claw back Python overhead.
Speculative decoding: the real differentiator
Speculative decoding (Leviathan et al., 2023) = a small, fast “draft” model guesses the next several tokens, and the big model verifies them all in one parallel pass. When the guesses are good, you generate multiple tokens per expensive forward pass instead of one. Net effect: 2–3×+ faster generation for latency-sensitive, single-stream use.
TRT-LLM has invested heavily here and ships the broadest menu: draft-model speculation, Medusa, EAGLE-3, Multi-Token Prediction (MTP) (notably for DeepSeek), and n-gram methods. vLLM supports speculative decoding too, but TRT-LLM’s matrix is wider and more aggressively tuned.
Quantization & parallelism
The widest hardware-aligned quant menu of the three, because it maps directly to NVIDIA’s quant hardware: FP8, NVFP4/FP4, INT4-AWQ, INT8-SmoothQuant, W4A8. Tensor, pipeline, and expert parallelism (including wide-EP for large MoE), multi-GPU and multi-node, coordinated via MPI or, increasingly, other orchestrators. Plus ecosystem hooks: AutoDeploy (an automated PyTorch→TRT-LLM path), a prototype Ray orchestrator, and tight Triton + Dynamo integration.
One sharp edge worth flagging: TRT-LLM is the one engine here that historically doesn’t ship an app-facing API on its own — it leans on Triton or a wrapper for that surface, though trtllm-serve has softened this.
Part 4 — Ray Serve, all the way down
Remember the framing: Ray Serve runs no forward pass. Everything here is around the engine.
The primitives
- Deployment — a Python class with
@serve.deployment. Model loading goes in__init__, inference in async methods. Independently scalable. - Replica — a running instance of a deployment, backed by a Ray actor (a stateful worker process). This is your unit of scale.
- Ingress —
@serve.ingresswraps a FastAPI router, so your HTTP surface is just FastAPI. Requests hit a proxy that routes to replicas.
Because everything is a composable Python class, a RAG pipeline — embedding → reranker → LLM → guardrails — is just a few deployments wired together with typed handle calls, each scaling on its own. That composition story is the whole reason Ray Serve exists.
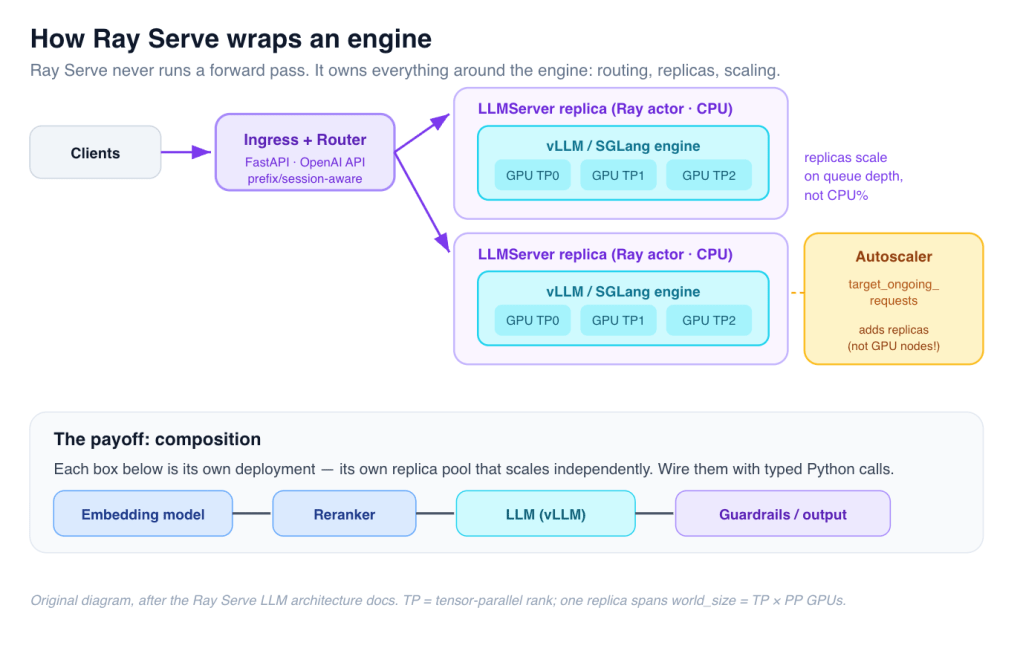
Figure 5 — A Ray Serve LLM replica is a CPU actor that owns a vLLM/SGLang engine and its GPU workers. The autoscaler adds replicas based on queue depth. (Original diagram, after the Ray Serve LLM docs.)
Ray Serve LLM — the engine wrapper
ray.serve.llm specializes the primitives for LLM workloads. The mechanics worth knowing:
- The replica actor itself takes
{CPU: 1}(no GPU), and requestsworld_size = tensor_parallel_size × pipeline_parallel_sizebundles of{GPU: 1}for the actual engine workers, packing TP ranks onto the same node when it can. - vLLM and SGLang both plug in behind an
LLMEngineprotocol, so the engine is swappable. - The OpenAI-compatible ingress scales separately from the engine. Anyscale recommends roughly a 2:1 ingress:engine ratio, because the ingress event loop becomes the CPU bottleneck before the GPUs do.
Autoscaling on the signal that matters
This is where Ray Serve is meaningfully better than naive Kubernetes HPA. Standard HPA scales on CPU utilization — useless here, because LLM serving pins the GPU while the CPU sits at 5%, and vLLM pre-allocates KV-cache VRAM so memory usage is flat regardless of load. Ray Serve autoscales on queue depth (target_ongoing_requests) — the thing that actually tracks GPU saturation.
One gotcha that bites people: Ray Serve adds replicas, it does not provision GPU nodes. Set max_replicas: 4 with two GPUs in the cluster and the other two replicas sit PENDING forever. You still need cluster-level provisioning (KubeRay + a cluster autoscaler, or pre-provisioned spare GPUs) for true elastic scale.
Orchestrating the hard topologies
The reason Ray Serve LLM got interesting in 2025–2026: serving big MoE models well needs wide expert parallelism and disaggregated prefill/decode, and both require coordination between engine instances — assigning data-parallel ranks, sharing an IP/port for the expert-parallel group, aligning KV-connector ports across heterogeneous prefill and decode pools. Ray Serve LLM exposes these as Python builder APIs (build_dp_deployment and friends) so you declare a wide-EP or disaggregated topology in a few lines instead of hand-wiring multi-pod coordination.
Closing the overhead gap
The old knock on Ray Serve was orchestration overhead versus a lean Rust router. Recent Ray (2.55/2.56) mostly erased it: a C-based HAProxy ingress, a direct-streaming mode that splits the routing control plane from the token-streaming data plane (HAProxy connects straight to the chosen replica after the routing decision), and Nagle’s algorithm disabled for streaming. Anyscale now reports Ray Serve LLM matching the vllm-router baseline on TTFT and throughput across prefill-heavy, decode-heavy, and agentic workloads. The overhead is no longer a good reason to avoid it — and you get fault tolerance, observability, and composition in exchange.
Part 5 — The low-level comparison, side by side
| Dimension | vLLM | TensorRT-LLM | Ray Serve (LLM) |
|---|---|---|---|
| KV cache | PagedAttention (block tables) | Paged KV cache + reuse | Delegated to engine |
| Batching | Continuous (iteration-level) | In-flight batching | Delegated |
| Scheduler | V1 unified token budget | C++/PyTorch IFB scheduler | Replica-level routing |
| Chunked prefill | Default in V1 | Supported | Delegated |
| Prefix caching | Yes (automatic) | Yes (KV reuse) | Prefix-aware routing on top |
| Speculative decoding | Yes | Yes — broadest (Medusa/EAGLE-3/MTP/n-gram) | Delegated |
| Quantization | FP8, AWQ, GPTQ, INT8, NVFP4 | FP8, NVFP4, INT4-AWQ, INT8-SQ, W4A8 | Delegated |
| Parallelism | TP, PP, DP+EP | TP, PP, wide-EP | Orchestrates engine TP/PP/EP across nodes |
| Disaggregated P/D | Yes (NIXL etc.) | Yes | Orchestrates it (builder API) |
| Setup | pip → serve | PyTorch path ≈ vLLM; legacy = build step | Write deployments, serve run |
| Cold start | Seconds | Seconds (PyTorch) / ~tens of min (compiled) | Engine start + cluster spin-up |
| Hardware | NVIDIA/AMD/TPU/CPU | NVIDIA only | Whatever the engine supports |
| Best at | Flexible high-throughput serving | Peak NVIDIA latency/throughput | Multi-model, multi-node, autoscaling |
Part 6 — The wider field (because it’s not just three)
You asked me to bring in the other players, and you’re right to — in 2026 the honest landscape is bigger.
Other engines
SGLang (pronounced “ess-gee-lang,” and yes, often just said “slang”) is the one that crept up on vLLM and, on a lot of workloads, passed it. It came out of Berkeley and LMSYS — partly the same people behind vLLM — but optimized for a different thing: structured LLM programs rather than independent requests. Its signature trick is RadixAttention, which keeps the KV cache around in a radix tree (think autocomplete index) so that any request sharing a prefix with a past one reuses the cached computation instead of redoing it.
When does that matter? Constantly, in modern apps: a 4,000-token system prompt repeated across thousands of requests, the same document hit by ten RAG queries, tool definitions that ride along on every agent step. Reported prefix cache-hit rates are dramatic — 85–95% for few-shot, 75–90% for multi-turn chat — versus much lower for vanilla prefix caching, which is why you’ll see “up to ~3–5× faster on DeepSeek-V3” and “~29% over vLLM on shared-prefix Llama-3.1-8B” claims. On unique prompts that edge mostly evaporates, so read those numbers as workload-shaped. SGLang also has best-in-class constrained decoding (fast JSON/grammar via xGrammar) and now reportedly powers serving at xAI, LinkedIn, Cursor, and others. The trade-off: smaller community than vLLM, so fewer Stack Overflow answers at 2 a.m., and an API that moves fast.
LMDeploy (from the InternLM team) is the quiet performance monster. Its TurboMind backend is pure C++ with no Python in the hot path, and on H100 it trades blows with SGLang at the top of throughput charts — while keeping low TTFT and strong INT4 support. Great pick if you want maximum Hopper performance without TRT-LLM’s operational weight, especially for quantized inference.
TGI (HuggingFace Text Generation Inference) was a top contender a year ago and is now in maintenance mode (since around December 2025); HuggingFace themselves point new users to vLLM or SGLang. If you’re still on it, treat that as your migration signal.
llama.cpp and Ollama are a different category entirely — accessibility, not datacenter scale. llama.cpp is a dependency-light C/C++ implementation that runs on basically anything (x86, ARM, Apple Silicon via Metal, NVIDIA via CUDA, AMD via ROCm), with first-class quantization and the portable single-file GGUF format. Ollama wraps it in a friendly developer experience. Neither does continuous batching, so neither is your answer for high concurrent load — but for local dev, CPU-only boxes, Macs, or air-gapped deployments, they’re exactly right.
MLC-LLM is the one to reach for when you need edge, mobile, or in-browser inference — it compiles models to run across an unusually wide set of targets. Aphrodite and ExLlamaV3 round out the enthusiast/throughput-niche end.
| Engine | Signature trick | Sweet spot | Watch out for |
|---|---|---|---|
| vLLM | PagedAttention | Flexible, broad-hardware production default | Last few % of peak perf |
| TensorRT-LLM | Compiled kernels + Transformer Engine | Peak NVIDIA perf, stable model | NVIDIA-only; legacy build step |
| SGLang | RadixAttention | Shared-prefix: RAG, agents, multi-turn | Smaller community, fast-moving API |
| LMDeploy | TurboMind C++ | Max Hopper throughput, INT4 | Narrower model coverage |
| TGI | (HF ecosystem) | — (maintenance mode) | Migrate off for new work |
| llama.cpp / Ollama | GGUF + portability | Local, CPU, Mac, edge, dev | No continuous batching → not for scale |
| MLC-LLM | Cross-platform compile | Edge / mobile / browser | Specialized |
Other orchestrators
Ray Serve isn’t the only thing that can sit on top of an engine.
NVIDIA Dynamo is the big one to know. Announced at GTC 2025, it’s NVIDIA’s open-source, datacenter-scale distributed inference framework — and it explicitly positions itself as the orchestration layer above engines, supporting vLLM, SGLang, and TensorRT-LLM as interchangeable backends. It does LLM-aware (KV-cache-aware) request routing, disaggregated prefill/decode with a smart planner, GPU-to-GPU KV transfer via NIXL, and memory tiering to cheaper storage. It’s the spiritual successor to Triton for the disaggregated era, and on GB200/GB300 NVL72 systems NVIDIA claims very large MoE throughput multipliers. If you’re all-in on NVIDIA at fleet scale, Dynamo is the direct alternative to Ray Serve.
Triton Inference Server is the older NVIDIA workhorse — a general model server (not LLM-specific) that hosts the TensorRT-LLM backend and standardizes deployment across frameworks. Still the standard way to productionize a compiled TRT-LLM engine.
llm-d is the Kubernetes-native one, introduced at Red Hat Summit 2025 by Red Hat with Google and others. Built on top of vLLM and the Inference Gateway, it brings disaggregated serving and KV-cache-aware scheduling to vanilla Kubernetes, leaning on NVIDIA NIXL for the fast KV transfers. If your world is k8s-first and vLLM-based, llm-d is aimed squarely at you (with the caveat, noted in the research literature, that it inherits vLLM’s one-model-per-node assumptions).
KServe and BentoML round out the picture — more general model-serving platforms that can front LLM engines, strong if you’re standardizing all model serving (not just LLMs) on one control plane.
The pattern across all of these: the orchestrator is engine-agnostic by design. You pick an engine for raw performance and an orchestrator for everything around it, and the good orchestrators treat the engine as a swappable part.
Part 7 — What the benchmarks actually say
Numbers swing hard with hardware, model, prompt-sharing pattern, and config, so read shape, not just rank. A representative single-H100 study (Spheron, early 2026; Llama-class models, ~512-token inputs / ~256-token outputs, unique prompts) found:
- TensorRT-LLM leads raw throughput at every concurrency level once compiled — smallest gap at low concurrency (~8% over vLLM at one request), widest at high concurrency (~13% at 50). It also posts the lowest p50/p95 TTFT, and the p95 gap matters most under heavy load.
- SGLang sits between TRT-LLM and vLLM, and pulls clearly ahead specifically when requests share prefixes. On unique prompts (as in that run) its RadixAttention edge mostly disappears. On a separate ShareGPT-style H100 run, SGLang and LMDeploy clustered around ~16,200 tok/s versus vLLM’s ~12,500 — a ~29% gap attributed to scheduling/orchestration overhead, not the math kernels.
- vLLM is the strong, flexible baseline. Several published vLLM rows predate its newest scheduler path, so treat them as a floor rather than a ceiling — and in some TTFT tests vLLM has actually shown the lowest time-to-first-token.
Two things I’d put on a sticky note:
- Single-request latency benchmarks tell you almost nothing about behavior at 50–100 concurrent users. Look at throughput and TTFT/TPOT under concurrent load, period.
- The “winner” flips with workload shape. Shared prefixes → SGLang. Fixed-shape sustained NVIDIA traffic → TRT-LLM. Heterogeneous, bursty, model-churning traffic → vLLM’s flexibility.
And Ray Serve isn’t in these charts because it isn’t an engine. Its relevant benchmark is orchestration overhead versus vllm-router (now roughly at parity), not tokens/sec.
Part 8 — How to actually choose
Pick the engine first, then decide whether you need an orchestrator. Here’s the decision I’d walk a teammate through:
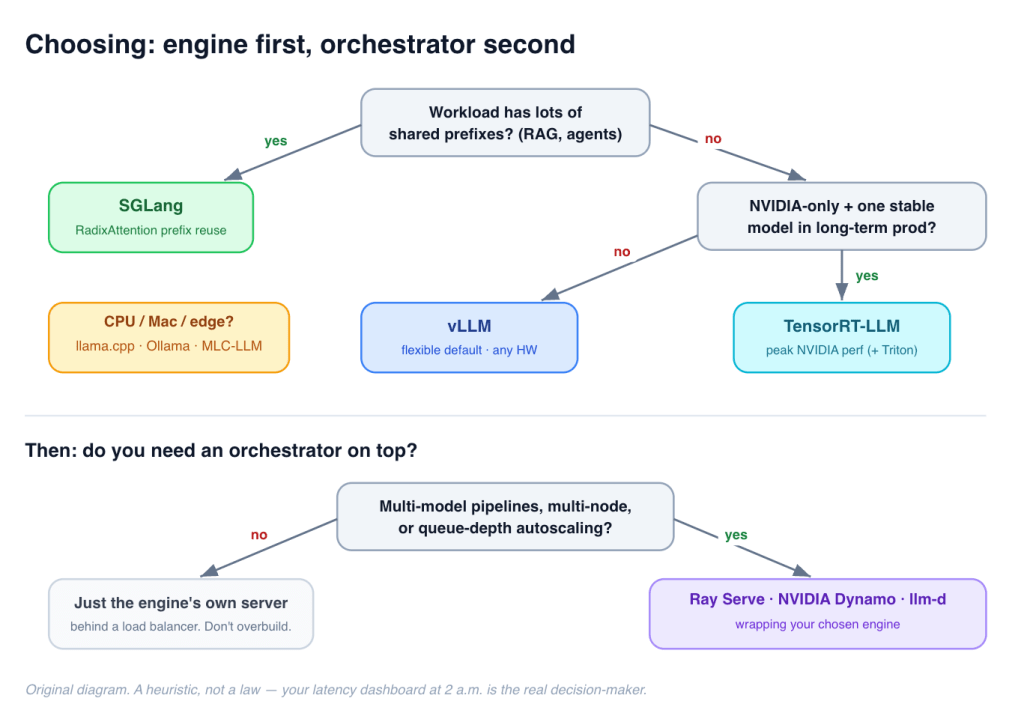
Figure 6 — Engine first, orchestrator second. A heuristic, not a law. (Original diagram.)
Reach for vLLM if you change models often, run a mix of models or LoRA variants, aren’t exclusively on NVIDIA, or just want the fastest path from pip install to a running endpoint. It’s the right default for most teams, and the safe answer if you don’t already have strong opinions. You’ll know when you’ve outgrown it, because you’ll be staring at a P99 dashboard wondering why.
Reach for TensorRT-LLM if you’re NVIDIA-only and latency/throughput is the product, you have a stable model in long-term production where a one-time optimization cost amortizes, or you want maximal FP8/FP4 exploitation and the richest speculative-decoding menu. And re-evaluate it even if you wrote it off pre-2025 — the PyTorch default removed most of the old friction.
Reach for SGLang if your traffic is dominated by shared prefixes — chatbots with big system prompts, RAG, multi-turn agents. RadixAttention is the difference-maker, and this is the workload the other two split.
Reach for LMDeploy if you want top-of-chart Hopper throughput or INT4 efficiency without TRT-LLM’s operational weight. llama.cpp / Ollama / MLC-LLM if the target is CPU, Mac, edge, or browser.
Then, add an orchestrator only if you need multi-model pipelines, autoscaling on queue depth, or multi-node topologies (pipeline parallel across nodes, disaggregated P/D, wide-EP). For that, Ray Serve (Python-native, engine-agnostic, great composition), NVIDIA Dynamo (NVIDIA-fleet-scale disaggregation), or llm-d (Kubernetes-native, vLLM-based). Skip the orchestrator entirely if you’re serving one model on a handful of GPUs with no branching pipeline — the engine’s own server behind a load balancer is far less to operate. Don’t pay orchestration complexity for a single-replica deployment.
The common production shapes, to make it concrete:
- One model, NVIDIA, max perf → TensorRT-LLM + Triton.
- Flexible single/few models → vLLM standalone server.
- Many models / pipelines / multi-node autoscaling → Ray Serve LLM wrapping vLLM (the most common “all three” setup — except it’s two layers, not a competition).
- Datacenter-scale disaggregated MoE → vLLM or TRT-LLM engines under Dynamo or Ray Serve.
Part 9 — The 2026 convergence
The most interesting thing about this whole space right now is that the lines are blurring:
- TensorRT-LLM went PyTorch-native (1.0, Sept 2025), erasing most of the usability gap that defined the vLLM-vs-TRT-LLM debate for years.
- Disaggregated prefill/decode is now table stakes across vLLM, TRT-LLM, SGLang, and Dynamo — it’s a standard, not a differentiator.
- Everyone’s converging on the same orchestration patterns. TRT-LLM ships a prototype Ray orchestrator; vLLM uses a Ray executor backend by default for multi-node; Ray Serve and Dynamo both treat engines as swappable parts behind a protocol.
- The engines increasingly share the same kernels (FlashAttention, FlashInfer) and the same algorithmic ideas (paged KV, continuous batching, speculative decoding, prefix reuse).
So the durable way to reason about it — and the thesis I’d lead a talk with — is by layer and by lock-in, not by leaderboard:
- vLLM is the flexible, portable engine. Bet on it when model and hardware churn is your reality.
- TensorRT-LLM is the NVIDIA performance ceiling. Bet on it when the model is stable and the silicon is fixed.
- Ray Serve (or Dynamo, or llm-d) is the substrate that makes either of those survivable at fleet scale.
They’re not three answers to one question. They’re answers to different questions — and a well-built 2026 stack usually runs one engine plus one orchestrator, not one of three rivals.
Glossary
Short definitions for the concepts above, each with somewhere to read more.
- KV cache — cached attention keys/values for all prior tokens, so the model doesn’t recompute history every step. Dominates serving-time GPU memory. (primer)
- Prefill / decode — prompt-processing phase (parallel, compute-bound) vs token-generation phase (sequential, memory-bandwidth-bound).
- TTFT / TPOT / ITL — time to first token; time per output token / inter-token latency. The two halves of perceived latency.
- PagedAttention — KV cache split into fixed-size blocks mapped via a block table, OS-virtual-memory style. (Kwon et al., SOSP 2023)
- Continuous / in-flight / iteration-level batching — re-schedule the batch every forward pass; refill finished slots immediately. (Orca, OSDI 2022)
- Chunked prefill — split long prompts into chunks interleaved with decodes to protect tail latency. (SARATHI)
- Prefix caching — reuse KV for shared leading tokens (e.g. a common system prompt) across requests.
- RadixAttention — SGLang’s radix-tree prefix cache that reuses shared computation across requests. (SGLang paper)
- Speculative decoding — a draft model proposes tokens the big model verifies in parallel; multiple tokens per forward pass. (Leviathan et al.)
- Disaggregated prefill/decode — run the two phases on separate GPU pools, transferring KV between them. (Splitwise, DistServe)
- Quantization — fewer bits per weight/activation/KV (FP8, FP4, INT4, AWQ, GPTQ, SmoothQuant) for speed and memory at small accuracy cost.
- Tensor / pipeline / expert / data parallelism — split-a-layer / split-by-layer / split-the-experts / full-replicas, respectively.
- MoE (Mixture of Experts) — models like DeepSeek-V3 where each token routes to a few of many “expert” subnetworks; cheap to run relative to size, but awkward to serve.
- FlashAttention — IO-aware exact-attention kernel that avoids materializing the full attention matrix. (Dao et al.)
- CUDA graphs — capture a sequence of GPU ops once and replay them to kill per-step launch overhead.
- Transformer Engine — NVIDIA’s FP8/FP4 acceleration library for Hopper/Ada/Blackwell. (docs)
- NIXL — NVIDIA Inference Xfer Library; fast GPU-to-GPU KV-cache transfer used in disaggregated serving.
- Ray actor — a stateful Ray worker process; the thing a Ray Serve replica runs as.
References
Primary sources I leaned on, grouped roughly by topic. Where a vendor’s claim is involved, I’ve linked the vendor so you can check the framing yourself.
vLLM & PagedAttention
- Kwon et al., “Efficient Memory Management for LLM Serving with PagedAttention,” SOSP 2023 — https://dl.acm.org/doi/10.1145/3600006.3613165 · https://arxiv.org/abs/2309.06180
- vLLM V1 announcement — https://blog.vllm.ai/2025/01/27/v1-alpha-release.html
- vLLM V1 user guide — https://docs.vllm.ai/en/stable/usage/v1_guide/
- Aleksa Gordić, “Inside vLLM: Anatomy of a High-Throughput LLM Inference System” — https://www.aleksagordic.com/blog/vllm
- Yu et al., “Orca: A Distributed Serving System for Transformer-Based Generative Models,” OSDI 2022 — https://www.usenix.org/conference/osdi22/presentation/yu
- Agrawal et al., “SARATHI” (chunked prefill) — https://arxiv.org/abs/2308.16369
TensorRT-LLM
- TensorRT-LLM GitHub & 1.0 release notes — https://github.com/NVIDIA/TensorRT-LLM
- TensorRT-LLM docs (LLM API, PyTorch backend, trtllm-serve) — https://nvidia.github.io/TensorRT-LLM/
- Jun Yang, “On the Release of TensorRT-LLM 1.0” — https://medium.com/@juney_84114/on-the-release-of-tensorrt-llm-1-0-addabae83496
- Leviathan, Kalman, Matias, “Fast Inference from Transformers via Speculative Decoding” — https://arxiv.org/abs/2211.17192
Ray Serve
- Ray Serve LLM architecture overview — https://docs.ray.io/en/latest/serve/llm/architecture/overview.html
- Anyscale, “Ray Serve LLM: Wide-EP and Disaggregated Serving with vLLM” — https://www.anyscale.com/blog/ray-serve-llm-anyscale-apis-wide-ep-disaggregated-serving-vllm
- Anyscale, “High Performance Distributed Inference with Ray Serve LLM” — https://www.anyscale.com/blog/high-performance-distributed-inference-ray-serve-llm-vllm-google-kubernetes-gke
Other engines & orchestrators
- SGLang / RadixAttention paper — https://arxiv.org/abs/2312.07104
- NVIDIA Dynamo — https://developer.nvidia.com/dynamo · https://developer.nvidia.com/blog/introducing-nvidia-dynamo-a-low-latency-distributed-inference-framework-for-scaling-reasoning-ai-models/
- NVIDIA on llm-d — https://developer.nvidia.com/blog/nvidia-dynamo-accelerates-llm-d-community-initiatives-for-advancing-large-scale-distributed-inference/
Disaggregation
- Patel et al., “Splitwise” — https://arxiv.org/abs/2311.18677
- Zhong et al., “DistServe” — https://arxiv.org/abs/2401.09670
Benchmarks (read as workload-shaped snapshots, not verdicts)
- Spheron, “vLLM vs TensorRT-LLM vs SGLang: H100 Benchmarks (2026)” — https://www.spheron.network/blog/vllm-vs-tensorrt-llm-vs-sglang-benchmarks/
Foundational
- Dao et al., “FlashAttention” — https://arxiv.org/abs/2205.14135
