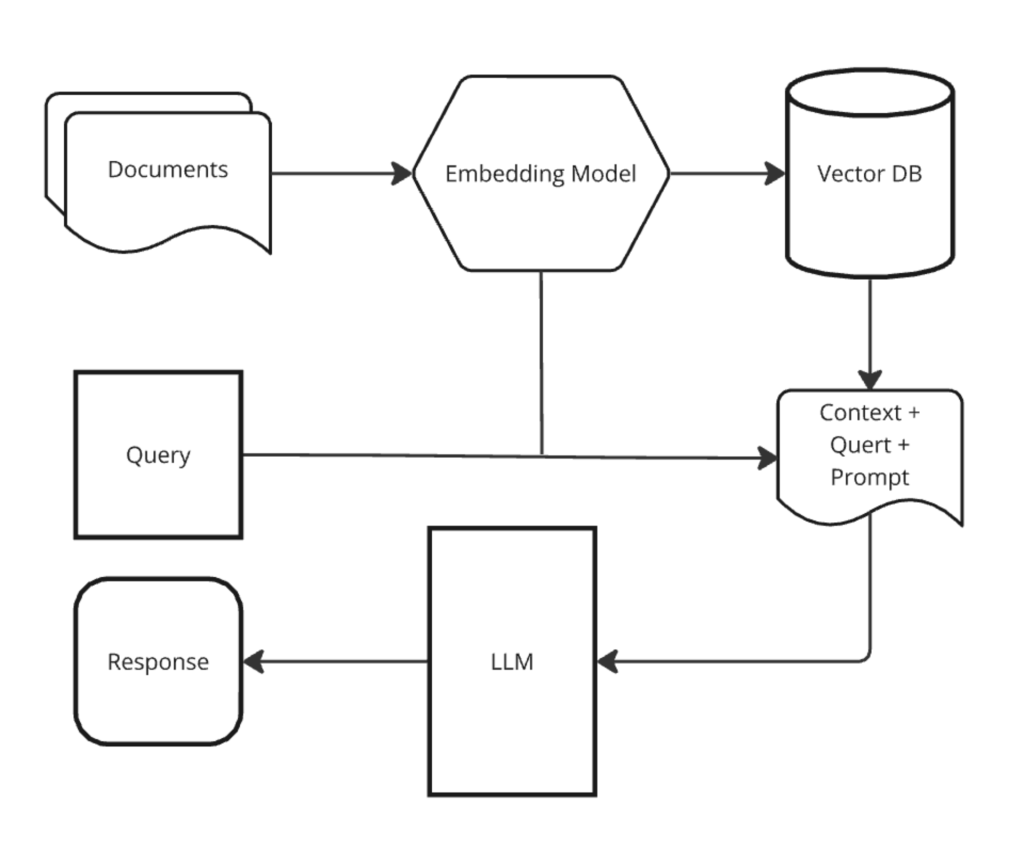
In the fast-evolving field of AI, Retrieval-Augmented Generation (RAG) has become a standout technique by effectively bridging the gap between information retrieval and text generation. Essentially, a RAG system retrieves relevant documents from a large corpus in response to a user query, then uses a generative model to produce a coherent response grounded in the retrieved data. This dual system—retrieval followed by generation—requires careful calibration to achieve high-quality outputs. Each step in this pipeline presents unique challenges that can significantly impact the system’s overall performance if not properly addressed.
Embedding Quality: The Foundation of Effective Retrieval
Embeddings are the cornerstone of the retrieval process in a RAG system. These dense vector representations capture the semantic meanings of text, going beyond simple keyword matching. For example, the sentences “The cat is on the mat” and “A feline is sitting on the mat” should be close in vector space despite having no common words. If embeddings are poorly tuned, the system may retrieve irrelevant documents, which is particularly problematic when the generative model relies heavily on this retrieved context to produce accurate responses.
To construct these embeddings, models like BERT are commonly used. Text is passed through these models, and the output vectors, often from the last layer, are averaged to create a single vector representing the text. Fine-tuning these embeddings on domain-specific datasets can greatly improve their relevance. For instance, in legal applications, fine-tuning on legal texts can enhance retrieval accuracy. In practice, embeddings can be visualized using dimensionality reduction techniques like t-SNE, allowing developers to inspect how well the model groups semantically similar documents.
Retrieval Accuracy: The Heart of RAG
Once embeddings are established, the next crucial step is retrieval, where the goal is to accurately select the most relevant documents for the generative model to use. This is where the choice between sparse and dense retrieval methods becomes critical.
Sparse retrieval methods like TF-IDF or BM25 rely on keyword matching. They are fast and effective for exact matches but often miss the nuances of language, such as synonyms or paraphrasing. For example, a sparse retrieval method might miss documents that discuss “patent infringements” if the exact phrase “intellectual property disputes” is not present in the query. On the other hand, dense retrieval uses embeddings to find semantically similar documents. While more computationally expensive, this method is more likely to retrieve documents that are contextually relevant to the query.
In a legal RAG system, for example, a query asking for cases related to “intellectual property disputes” might benefit significantly from dense retrieval, as it would likely capture documents discussing related concepts like “patent infringements” through their semantic similarity.
The Art of Prompt Engineering
Even with high-quality retrieval, the final output from a RAG system hinges on how well the generative model is guided, which is where prompt engineering plays a vital role. A prompt is a structured input that directs the model on how to use the retrieved documents.
The challenge here is avoiding hallucinations, where the model generates content not supported by the retrieved documents. A poorly designed prompt might lead the model to include information that isn’t present in the retrieved documents. For example, a generic prompt asking the model to “explain the query using the following documents” might inadvertently encourage the generation of unsupported information. Instead, a more specific prompt instructing the model to “only use the information in the retrieved documents to answer the query” can significantly reduce the likelihood of hallucinations.
Effective prompt engineering is not a one-time task but involves iterating on different prompt designs and testing their effectiveness. This process requires a deep understanding of how the model interprets prompts and how different structures can influence the output.
Scalability and Performance Monitoring
As the size of the corpus grows, maintaining the performance of a RAG system becomes increasingly challenging. The retrieval component, in particular, can become a bottleneck, leading to slower response times and potential drops in accuracy.
To handle large corpora efficiently, scalability strategies like Approximate Nearest Neighbor (ANN) search can be employed. Techniques such as FAISS or ScaNN allow for faster retrieval by approximating the nearest neighbors rather than finding exact matches, significantly improving scalability without sacrificing much accuracy. In large-scale systems, distributing the corpus across multiple nodes and running retrieval processes in parallel can further reduce the load on individual nodes, ensuring faster retrieval times.
Continuous performance monitoring is also crucial. There are enormous number of LLM observability, evaluation, and monitoring tools out there to use in your RAG application.
Handling Ambiguity and Data Sparsity
RAG systems often encounter challenges when dealing with ambiguous queries or sparse data. Ambiguity in user queries can lead to confusion in both retrieval and generation, resulting in outputs that are either too vague or completely off the mark.
To resolve ambiguity, techniques such as query disambiguation or expansion can be employed. For example, if a user query is ambiguous, the system might return multiple clarifying questions or results, asking the user to specify their intent further. When relevant data is sparse, the system may struggle to retrieve enough context to generate a meaningful response. In such cases, data augmentation techniques, such as generating synthetic data to fill gaps or leveraging external knowledge bases, can help improve the quality of retrieval and generation.
Fine-Tuning and Continuous Improvement
Building a high-performing RAG system is an ongoing process that requires continuous fine-tuning of both the retrieval and generative components. Regular updates to embeddings and iterative training of the generative model on new data are essential to adapt to evolving user needs and data landscapes.
For instance, a news RAG system might need frequent updates to handle the latest topics and events accurately. Incorporating user feedback into the fine-tuning process ensures that the system evolves in line with user expectations and real-world requirements. This feedback can be used to identify and correct biases, improve retrieval relevance, and refine prompt engineering.
Conclusion
Constructing a RAG system is a complex endeavor that involves navigating a series of challenges, from ensuring the quality of embeddings to balancing retrieval accuracy and managing scalability. These challenges, while significant, are not insurmountable. By carefully addressing each component and continuously monitoring and refining the system, developers can build RAG systems that deliver high-quality, contextually appropriate responses. The journey of building a RAG system is one of constant learning and adaptation, but the rewards—an AI system capable of nuanced, relevant, and dynamic generation—are well worth the effort.
This deep dive into the intricacies of RAG systems should provide a clear roadmap for tackling the challenges associated with building and maintaining these complex AI systems. The key to success lies in a detailed understanding of each component, continuous improvement, and a willingness to iterate and refine the system over time.
