
As the demand for large language models (LLMs) continues to rise, optimizing inference performance becomes crucial. vLLM is an innovative library designed to enhance the efficiency and speed of LLM inference and serving. This blog post explains a high level view of vLLM’s capabilities, its unique features, and how it compares to similar solutions in the field. In part-2 of this blog post we will have a deep dive into the techniques which made it possible for vLLM to out beat the competition.
What is vLLM?
vLLM is an open-source tool created to optimize the inference and serving of large language models by boosting throughput and reducing memory usage. It efficiently manages memory and execution processes to meet the needs of large-scale models. vLLM is compatible with a variety of model architectures and integrates easily with popular frameworks like Hugging Face Transformers, providing a versatile solution for developers.
Key Features of vLLM
PagedAttention
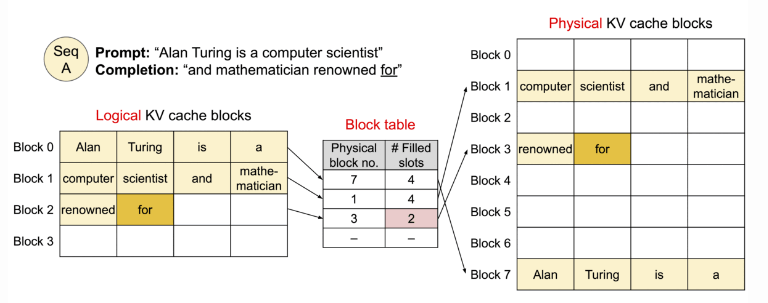
PagedAttention is a defining feature of vLLM, designed to address the memory inefficiencies of traditional attention mechanisms in LLMs. Instead of storing key-value (KV) caches in contiguous memory, which can be inefficient and memory-intensive, PagedAttention breaks the KV cache into non-contiguous blocks, akin to the paging system in operating systems. This reduces memory fragmentation, allowing more sequences to be processed simultaneously and optimizing memory use.
Continuous Batching and High Throughput

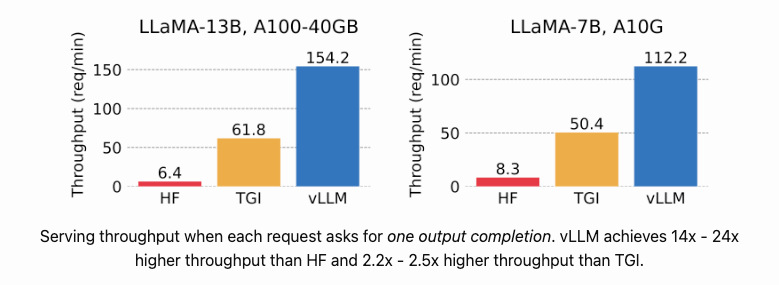
vLLM uses continuous batching, a strategy that dynamically groups incoming requests for efficient processing. This approach significantly boosts throughput compared to other serving frameworks like Hugging Face Transformers and TensorRT-LLM. Benchmark tests have shown that vLLM can achieve up to 24 times the throughput of some existing solutions.
Flexible Deployment Options
vLLM offers a variety of deployment configurations, including setups for single-node multi-GPU and multi-node distributed inference. It supports both tensor and pipeline parallelism, enhancing resource utilization and scalability. This flexibility makes it suitable for a range of environments, from local testing to large-scale production deployments.
How vLLM Works
Optimizations and Mechanisms
- PagedAttention: This unique feature allows vLLM to manage memory efficiently by dividing KV caches into blocks stored in non-contiguous memory spaces. This method minimizes memory waste and allows larger batch sizes.
- KV Cache Management: vLLM optimizes the handling of KV caches, which consume significant memory during inference. By adopting a block-based allocation system, vLLM reduces fragmentation and enhances memory efficiency.
- Dynamic Scheduling: The library uses dynamic scheduling to manage inference requests, enabling it to batch and process requests flexibly. This feature helps maintain high throughput even with fluctuating workloads.
Comparison with Other Solutions
vLLM vs. Hugging Face Transformers
While Hugging Face Transformers is a popular library with a comprehensive ecosystem of pre-trained models and tools, it can face limitations in memory and throughput during inference. vLLM addresses these challenges with its advanced memory management and continuous batching, making it a more efficient option for high-performance inference tasks.
vLLM vs. TensorRT-LLM
TensorRT-LLM focuses on optimizing LLM inference by using NVIDIA’s TensorRT framework for faster performance. Although TensorRT-LLM provides notable speed improvements on compatible hardware, vLLM’s PagedAttention and batching strategies offer superior memory efficiency and flexibility, especially for models requiring extensive KV cache handling.
Conclusion
vLLM marks a significant advancement in LLM inference, providing unmatched performance and memory efficiency. Its innovative features, such as PagedAttention and continuous batching, distinguish it from conventional solutions, making it a prime choice for developers aiming to optimize LLM deployments. As the need for scalable and efficient AI solutions grows, tools like vLLM will play a vital role in meeting these challenges and enabling the next generation of AI applications. In the next blog post we will have a deep dive into the optimization techniques that made vLLM so efficient. Stay tuned!
References
- vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention | vLLM Blog vLLM Blog.
- Welcome to vLLM! — vLLM vLLM Documentation.
- GitHub – vllm-project/vllm: A high-throughput and memory-efficient inference and serving engine for LLMs GitHub.
- Efficient Memory Management for Large Language Model Serving with PagedAttention [VLLM Paper].
